17
年資訊科技 (IT) 行業經驗
37
個曾參與的IT項目
7
個公司/品牌創始人
4
間公司的IT顧問
客戶是如何評價Ryan

香港大型寵物用品連鎖店 Petline
前行銷 (Marketing) 部門主任
Jam
Ryan自家開發的客製化電郵推廣系統,功能非常廣泛,對於不算熟識IT的新手來說,是方便簡單容易上手的選擇。另配有系統紀錄數據分析,可一目了然地檢視推廣成效。最後,不得不讚賞Ryan對客戶的熱誠及有禮的態度,能適時地解答任何類型問題,是百分百的優秀服務水準!

尚游健康科技有限公司
創辦人
Katie
Ryan是位很盡責的IT顧問,問他的問題解答都十分詳盡,亦會很耐心地嘗試向我解釋一些深奧的IT術語,提供的IT建議方案都很有效。他的IT知識令我感覺十分專業!

創新遊戲活動平台 BALL ROOM
創辦人
Steve
Ryan提出的IT方案都是跟據我們實際的業務要求,並經過深思熟慮後,專門為我公司度身訂做的,最後成品亦証明十分適用於我們的業務!
關於 Ryan
Ryan在資訊科技界行業打拼了13年,其間作出過很多方面的嘗試,打工的公司類型包括軟體服務供應商 (software house)、私人公司、NGO、自家軟件產品開發商,另外亦有創作自家製的手機應用程式和網上軟件訂閱服務,更曾成功入選科學園的創業培育計劃,成為旗下的其中一間重點培養公司,此外亦曾創立初創企業,獲私人投資者注資入股。Ryan深信其深厚且堅實的業界經驗,絕對能夠有效幫助到擁有不同IT需求的各界別人士。因此,如您有IT方面的諮詢需要,請不要猶豫,立即聯絡Ryan進行諮詢吧,期待能夠與您合作!
2004 - 2007
就讀及畢業於香港科技大學
取得香港科技大學 Computer Science & Engineering 學士學位,副修數學。
憑「家居風水分析系統」獲得2007年度學系Best Final Year Project Award。

隨後先代表香港科技大學參加香港區的泛珠三角洲大學生計算機作品賽獲得亞軍獎狀。
之後再獲機會代表香港地區參加泛珠三角洲大學生計算機作品賽決賽,與其他地區的大學機構學生交流與一較高下,並獲得三等銅獎。
 P.S. 「東方日報」報章的報導把我的名字和我的project partner名字錯誤對掉了
P.S. 「東方日報」報章的報導把我的名字和我的project partner名字錯誤對掉了
2007 - 2010
於香港著名軟件系統開發公司Computer & Technologies Limited工作
學習正統資訊科技(IT)行業的方法論及具體實踐方式,曾參與多個政府部門/香港公營機構的系統開發工作,更曾參與規模達1千萬的項目,為該項目的核心開發成員。
2010 - 2012
於香港著名機構東華三院工作
任職系統開發及分析師,從零開始開發一套供機構內部使用的系統,為該項目的主管者,把之前在軟件系統開發公司學習的理論具體實踐執行起來,工作績效獲部門同事高度評價認同。
2012
於全球B2B採購平台Tradegood工作
負責該公司線上採購平網上台的開發工作,為項目的核心成員。
2012 - 2013
與朋友共同設立初創企業及成立優惠劵分享平台QShare
負責QShare手機應用程式的後台及網站的開發,此項目亦成功獲得香港科技園創業培育計劃(INCU-APP)的申請資助,為該計劃年度的最具潛力應用程式之一。
2014 - 現在
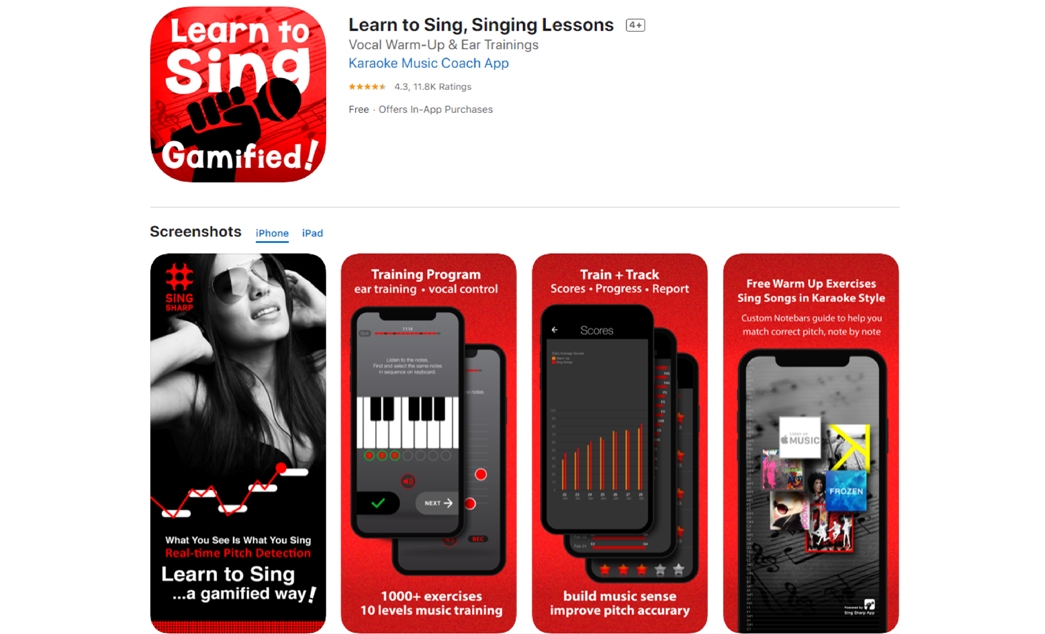
與朋友共同開發歌唱教學手機應用程式
Learn to Sing - Sing Sharp
為此手機應用程式的聯合創始人,負責Android以及後台的開發,此手機應用程式總下載人次超過500萬,iOS及Android總評分數量超過8萬條,2個平台評分皆超過4分 (5分為滿分)。
2015
與朋友共同設立另一初創企業及成立服務配對平台Hurry Hub
平台概念類似HelloToby,可惜最後由於內部人事問題,平台未能成功面世。負責此項目的手機應用程式(iOS及Android)以及後台開發工作,為項目的全端開發者 (Full Stack Developer)。
2016 - 現在
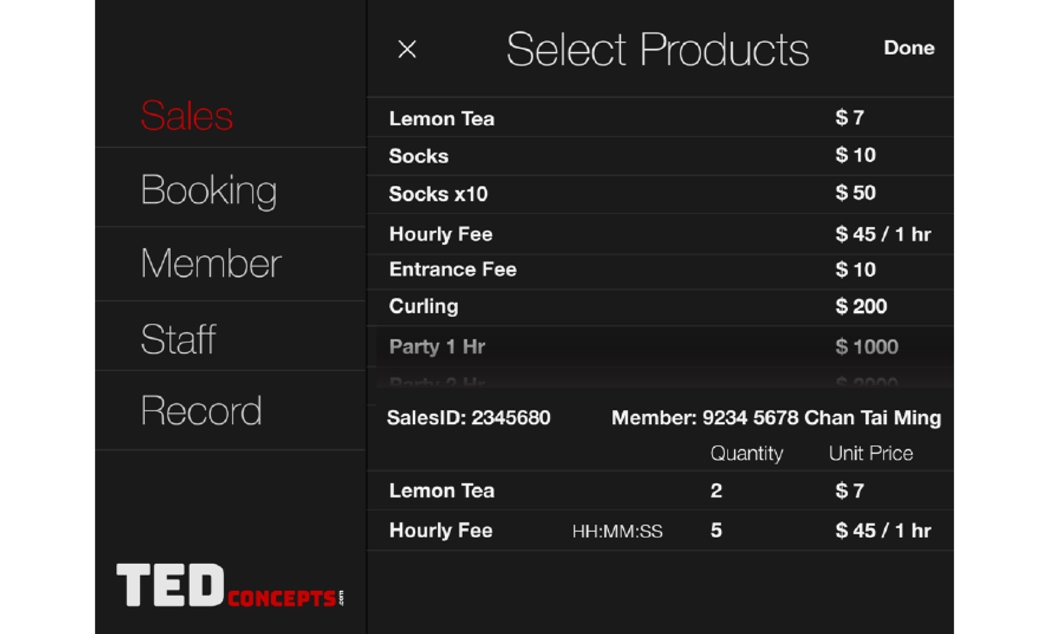
成立軟件系統開發公司
TED Concepts
把早前設立QShare的初創企業轉型成為軟件系統開發公司,服務範疇廣泛,包括網站系統、手機應用程式、電郵推廣 (Email Direct Marketing / EDM)、銷售時點情報系統 (Point of Sale / POS)、網站搜尋引擎優化 (Search Engine Optimization / SEO)、物聯網 (Internet of Things / IoT)等等。
![]()
2018
研發善用區塊鏈技術的智能合約生成平台 DINO
擔任此項目的首席科技總監兼區塊鏈開發者。以此平台技術為基礎提案,發行自家加密貨幣DINO Coin,作數字貨幣首次公開募資(Initial Coin Offering / ICO)的融資活動。此項目技術含量相當高,Ryan作為此項目的科技總監感覺獲益良多。
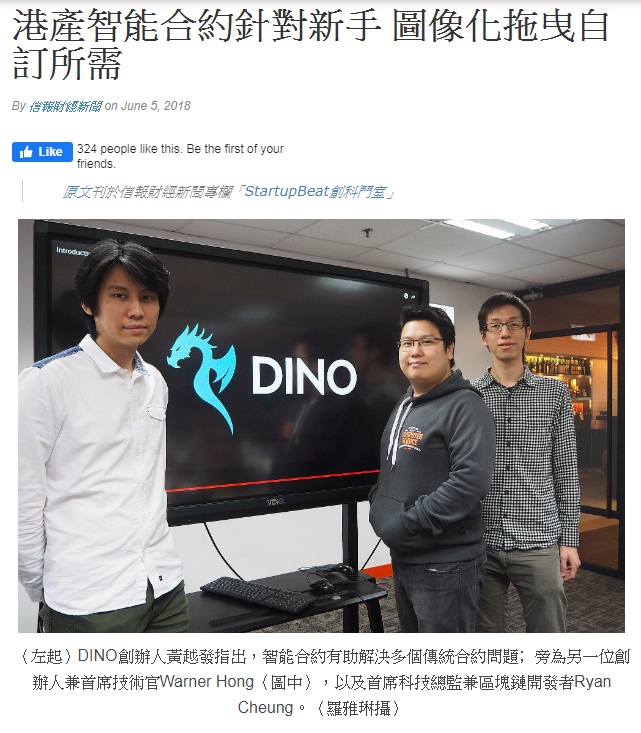 信報財經新聞 - 港產智能合約針對新手 圖像化拖曳自訂所需
信報財經新聞 - 港產智能合約針對新手 圖像化拖曳自訂所需
2019 2月
為女朋友創立瑜伽品牌 靜缽瑜伽 JB Yoga
開始自行學習數位行銷 (Digital Marketing),並積極試驗實踐當中理論,實現線上線下營銷模式 (O2O)。涉及範疇包括網站建設、社交媒體營運、數碼廣告、電郵推廣、線上會員計畫、文案創作、攝影、影片製作、印刷品製作宣傳等等。
2019 11月
創立課堂與客戶關係管理系統服務訂閱平台 Classtage
一套簡易上手的課堂與客戶關係管理、市場推廣、數碼行銷系統,5分鐘即可打造一套專屬於你業務的會員系統,內置行銷與推廣功能,讓你可以好好管理你的業務。此系統以訂閱服務形式收費,適合任何類型的授課人仕使用,每月只需付小量費用,即可擁有一套有效的課堂業務管理系統。
2020 9月
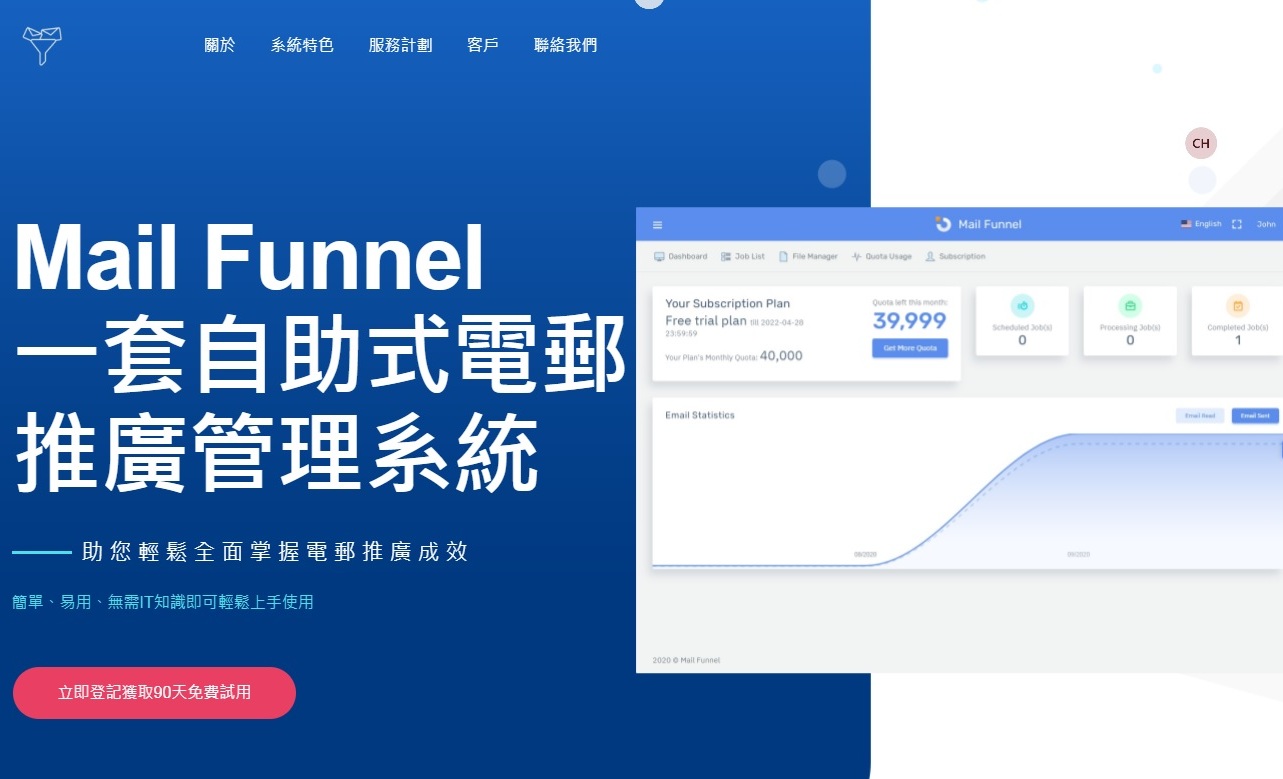
創立電子郵件推廣及行銷系統服務訂閱平台 Mail Funnel
一套自助式電郵推廣管理系統,助您輕鬆全面掌握電郵推廣成效,簡單、易用、無需IT知識即可輕鬆上手使用。
2021 5月
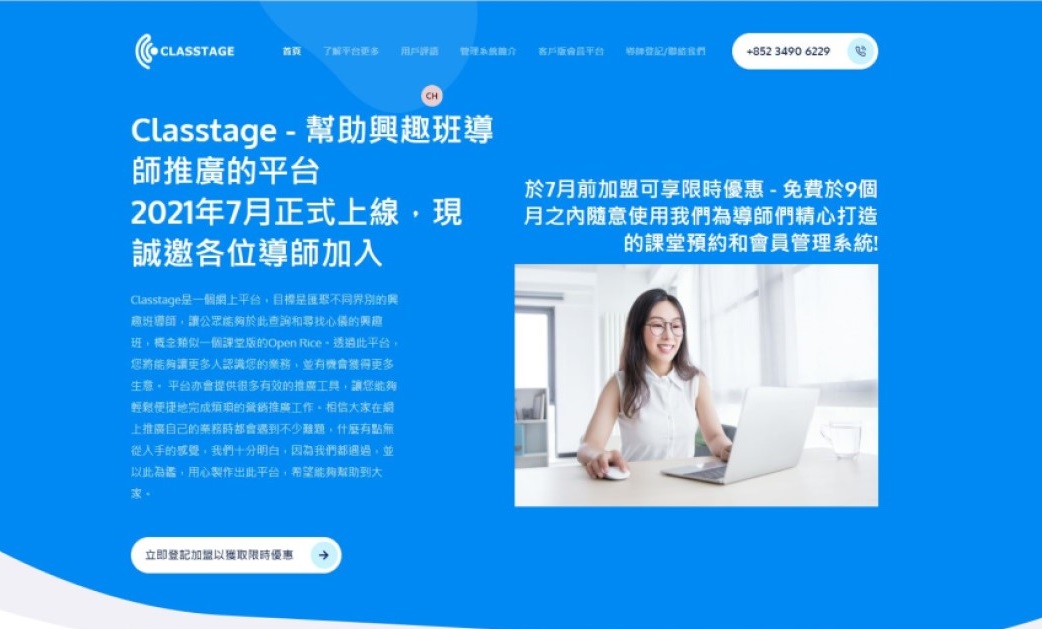
改造Classtage成為一個匯聚不同界別興趣班導師的網上平台
把Classtage變成為一個匯聚不同界別興趣班導師的網上平台,讓公眾能夠於此查詢和尋找心儀的興趣班,概念類似一個課堂版的Open Rice。透過此平台,興趣班導師將能夠讓更多人認識他/她的業務,並有機會獲得更多生意。平台亦保留原有的系統功能,提供很多有效的推廣工具,讓興趣班導師能夠輕鬆便捷地完成煩瑣的營銷推廣工作。
曾工作或服務過的機構
過往作品
以下是我其中一些較具代表性的工作成果